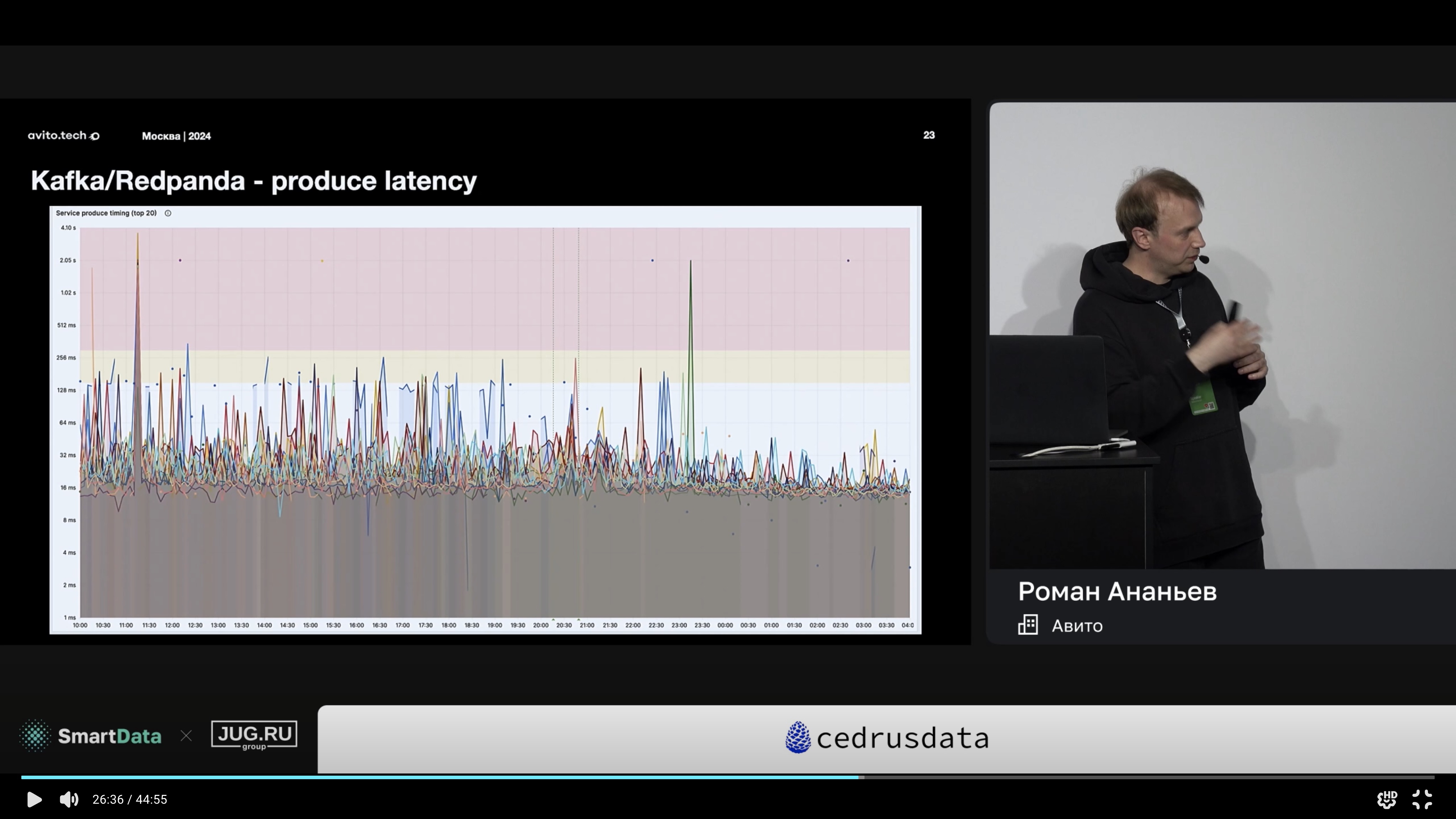
Redpanda написана на C++, поэтому by design может предоставлять более высокую, и что важнее, более стабильную производительность, нежели Kafka. Подробнее об этом в докладе «Как мы Apache Kafka на Redpanda меняли» на конференции SmartData от Романа Ананьева из Авито:
В правой части графика отражено применение Redpanda. Явно видно значительное снижение количества и размера задержек.
Помимо быстрого языка программирования задействован ряд довольно радикальных оптимизаций для работы в Linux. Во-первых, каждый процесс приложения привязывается к одному ядру, чтобы избежать расходов на переключение контекста. Во-вторых, оперативная память резервируется сразу в значительном объёме, игнорируя механизм Linux page cache. Это приводит к жесткому ограничению снизу на системные требования. Каждый брокер на старте рассчитывает минимум на:
2 ядра CPU (мотивируется это тем, что ядро с пандой может обрабатывать до 1 GB/сек, а скорость записи на NVMe SSD может быть выше, поэтому надо минимум два ядра);
Помимо этого каждая партиция потребует дополнительных 2 MB памяти, сверх того объёма, что требуется процессам самой панды. В свое время это поставило крест на идее держать отдельную партицию для каждого пользователя в системе трассировки событий Fractalog. Для 1000 пользователей потребуется дополнительных 2GB памяти на каждом брокере, т.е. с учетом Replica Factor равным 3 суммарно получим 6GB. Вместе с тем возможность быстро вытащить гарантированно упорядоченный в партиции трейс событий весь целиком и сразу выглядит очень заманчиво.
Моя локальная рабочая станция под управлением macOS обладает значительным объемом оперативной памяти (хвала небесам, успел приобрести до повального LLM-безумия, съевшего мировую оперативку), посему могу себе позволить экспериментировать с серверными технологиями, заточенными под HighLoad. Так в документации сказано, что панда за один присест съест не менее 4 GB оперативной памяти. Поехали!
Согласно документации, устанавливаем для macOS необходимое окружение. Требуется установить GNU tar:
# создаем директорию, чтобы не наследить в текущейmkdir redpanda-quickstart && cd redpanda-quickstart
# скачиваем архив с квикстартом панды и сразу же распаковываем его в текущую директорию, не создавая отдельного файла архива на дискеcurl -sSL https://docs.redpanda.com/redpanda-quickstart.tar.gz | tar xzf -
# в архиве лежит каталог docker-compose. Запускаем контейнер в фоновом режимеcd docker-compose && docker compose up -d
Некоторое время придется подождать, пока выполнится pull образов, создание сети и томов и далее запуск почти десятка контейнеров:
3 брокера redpanda, они формируют кластер, на троих сразу же скушали больше 2 GB памяти (dev-режим);
redpanda-connect и redpanda-console – платные утилиты, для которых предоставляется 30-дневный триал;
minio, нужен как объектное хранилище для механизма Tiered Storage Redpanda, который тоже входит в платный пакет. В продакшене MinIO не поддерживается, предлагается на выбор Amazon S3, Azure ADLS и Google GCS.
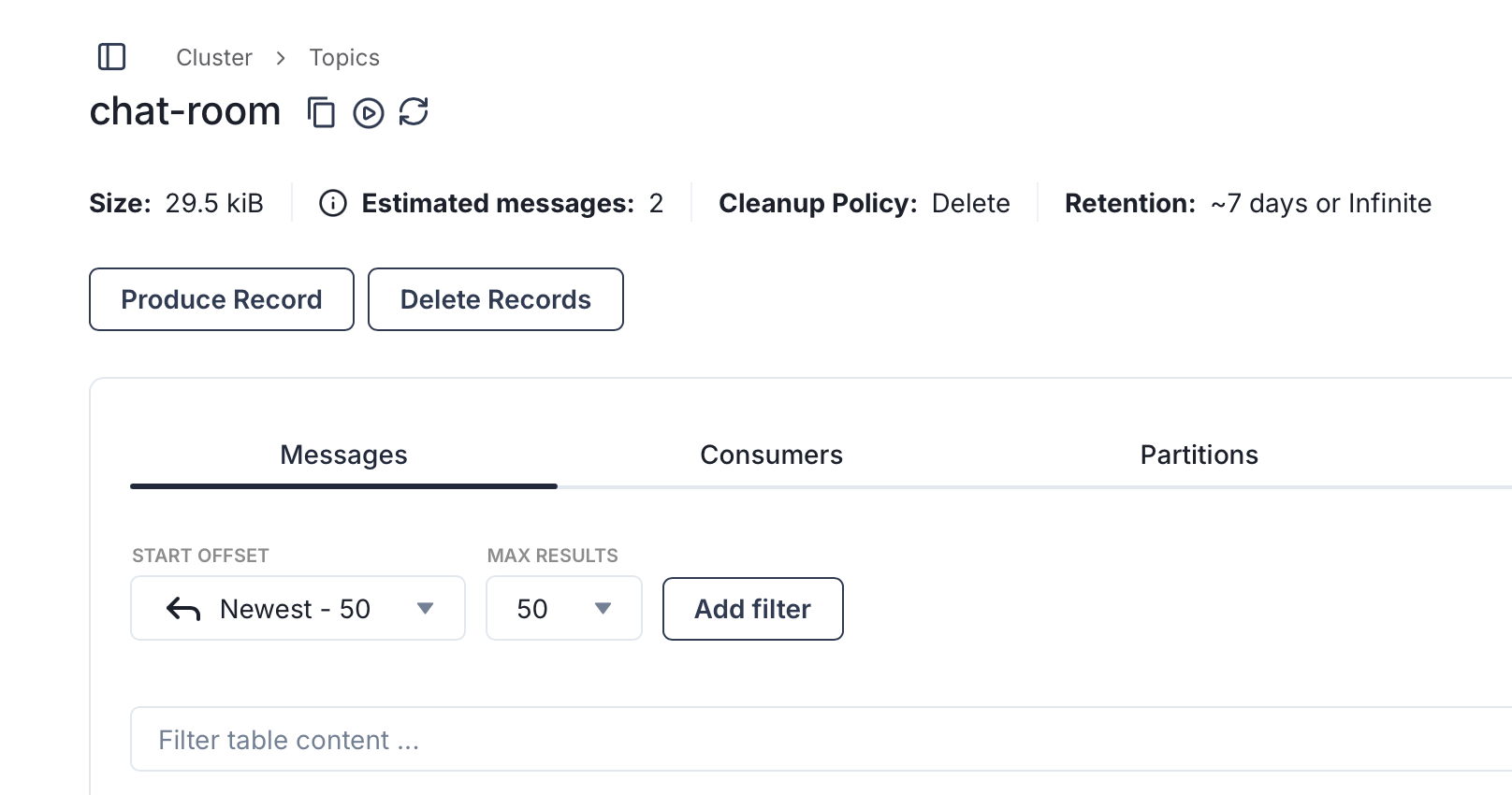
redpanda-console доступна через веб-интерфейс http://localhost:8080/login, запрашивает имя пользователя (superuser) и пароль (secretpassword). Консоль позволяет управлять топиками, просматривать их содержимое, настраивать JS-скрипты для обработки входящих данных и многое другое.
Меня же больше интересует API и доступ через терминал. Внутри каждого redpanda-контейнера лежит утилита CLI‑утилита rpk, которую можно запустить через оболочку docker exec. Например, вот так можно создать новый топик chat-room:
Копия rpk в каждом контейнере своя, при этом rpk ходит в кластер по Kafka API, а не только к «своему» брокеру. Каждая из копий может управлять всем кластером: создавать топики, смотреть состояние и т.д.
Можно установитьrpk напрямую, вне Docker-контейнера:
brew install redpanda-data/tap/redpanda
Инициализируем rpk с помощью конфигурационного файла rpk-profile.yaml, входящего в комплект поставки:
Значения в rpk-profile.yaml должны быть идентичны, чтобы утилита могла подключаться к кластеру:
# Configuration for connecting to the Kafka API of the Redpanda cluster.kafka_api:
# SASL (Simple Authentication and Security Layer) settings for authentication.sasl:
user: superuser# The username used for authenticationpassword: secretpassword# The password associated with the usernamemechanism: scram-sha-256# Authentication mechanism; SCRAM-SHA-256 provides secure password-based authentication# List of Kafka brokers in the Redpanda cluster.# These brokers ensure high availability and fault tolerance for Kafka-based communication.brokers:
- 127.0.0.1:19092 # Broker 1: Accessible on localhost, port 19092 - 127.0.0.1:29092 # Broker 2: Accessible on localhost, port 29092 - 127.0.0.1:39092 # Broker 3: Accessible on localhost, port 39092...
Утилита проинициализирована и готова к работе. Например, можно прочитать значения из топика:
rpk topic consume chat-room --num 10
Команда заблокирует терминал и будет висеть до тех пор, пока в топик не будет записано 10 и более значений, например, через веб-интерфейс redpanda-console:
Последующий вызов команды сразу вернет значения в терминал (повторное чтение топика) и завершит работу.
Утилита также может выступать в качестве продьюсера (набор флагов описан здесь). После ввода команды терминал будет ожидать текст, который будет записан в соответствующий топик:
Тонкие настройки кластера содержатся в файле bootstrap.yml. Задерживаться на них сейчас не будем, перейдем к взаимодействию между пандой и пользовательским кодом. В качестве основного языка для разработки backend я использую Go, поэтому удобно воспользоваться руководством для Go, доступным в документации. В качестве примера приводится реализация простейшего чата. Для взаимодействия с пандой в примере задействован Kafka-совместимый пакет franz-go.
Сначала получим список доступных топиков, проверяем наличие топика chat-room:
$ rpk topic list
NAME PARTITIONS REPLICAS
_redpanda.audit_log 123_redpanda.transform_logs 13_schemas 13chat-room 13edu-filtered-domains 11logins 11transactions 11
Если хотим задействовать rpk внутри контейнера, нужно указать логин-пароль для аутентификации SASL:
Пример из документации SASL не учитывает, поэтому исходники из примера тоже нужно дополнить указанием параметров для SASL для всех трех клиентов:
packagemainimport (
...// добавляем новый импорт"github.com/twmb/franz-go/pkg/sasl/scram"...)
typeAdminstruct {
client*kadm.Client}
funcNewAdmin(brokers []string) *Admin {
client, err:=kgo.NewClient(
kgo.SeedBrokers(brokers...),
// в каждый клиент добавляем SASL-параметрыkgo.SASL(scram.Auth{User: "superuser", Pass: "secretpassword"}.AsSha256Mechanism()),
...}
typeConsumerstruct {
client*kgo.Clienttopicstring}
funcNewConsumer(brokers []string, topicstring) *Consumer {
groupID:=uuid.New().String()
client, err:=kgo.NewClient(
kgo.SeedBrokers(brokers...),
// в каждый клиент добавляем SASL-параметрыkgo.SASL(scram.Auth{User: "superuser", Pass: "secretpassword"}.AsSha256Mechanism()),
...}
typeProducerstruct {
client*kgo.Clienttopicstring}
funcNewProducer(brokers []string, topicstring) *Producer {
log.Print("NewProducer")
client, err:=kgo.NewClient(
kgo.SeedBrokers(brokers...),
// в каждый клиент добавляем SASL-параметрыkgo.SASL(scram.Auth{User: "superuser", Pass: "secretpassword"}.AsSha256Mechanism()),
}
Название топика chat-room в примере захардкожено, если топик отсутствует, будет создан заново. Процесс записи в топик можно отследить через Redpanda Console.
Таким образом, franz-go предоставляет доступ к кластеру как на чтение, так и на запись. Осталось разобраться, как развернуть кластер на удаленном Linux (я использую Debian). Документация описывает разные варианты развертывания: Development/Test и Production. Конфигурации отличаются системными требованиями, для продакшена есть даже специальный чеклист.
…
Пора прикинуть бюджет. В документации рекомендуется 4 физических CPU-ядра для каждого брокера. 4 ядра * 2GB = 8GB оперативной памяти. Закладываем 2GB на нужды операционной системы с дополнительными сервисами (логгирование, мониторинг, SSH) и получаем суммарно 10GB. Допустим, что панда используется исключительно как «фильтр нагрузки на запись» перед OLAP-хранилищем. Предположим также, что каждый клиент генерирует 1Mb трафика в минуту и что у нас пиковый онлайн не более 10k пользователей. За минуту получим 10GB трафика, за час 600GB, дополнительно 20 GB закладываем на нужны операционной системы. Итого:
4 CPU Core;
10 GB DDR4;
620 GB NVMe.
Диск должен быть локальным, поскольку Network File System (NFS) не поддерживаются, а сетевой NVMe over TCP если и существует, то обходится в 3-4 раза дороже (если верить калькулятору от Selectel).
На момент подготовки этой статьи в феврале 2026 года стоимость аренды такого сервера составляет 8-12 тысяч рублей в месяц. Также рекомендуется Replica Factor держать равным 3, т.е. кластер обойдется в 24-36k рублей в месяц.